

Quasi un anno fa Matt Southern ha pubblicato un articolo sulle fluttuazioni del ranking per i nuovi contenuti John Mueller confermò il tutto ma ciò che rimaneva non detto era il motivo per cui i nuovi contenuti fluttuavano.
Se Google sta operando su un aggiornamento continuo, perché ci sono fluttuazioni?

John Mueller, come dicevamo, confermò subito che i nuovi contenuti rimbalzano nei risultati della ricerca prima di stabilirsi definitivamente e forse con oggi sappiamo anche il perché.
Riportiamo una interessante analisi fatta da Roger Montti su searchenginejournal.com (link in fondo alla pagina) che parte da ciò che il SEO Consultant ha potuto leggere in un post pubblicato su un gruppo privato di Facebook dove era stato chiesto perché le nuove pagine oscillavano.
I possibili motivi che sono stati offerti sono stati:
- Metriche utente
- Un punteggio PageRank temporaneo che viene successivamente aggiornato
- Clic sull’inserzione per verificare quanto fosse pertinente la pagina
Questi sono certamente degli ottimi suggerimenti sul perché il ranking delle nuove pagine fluttua così molto, tanto che esiste un brevetto depositato da Google chiamato “Modifying Search Result Ranking Based on Implicit User Feedback”.
Che tradotto potrebbe essere spiegato con un gioco di parole: modifica del risultato dei risultati di ricerca in base all’implicito feedback utente, ovvero il brevetto descrive il monitoraggio dei clic su una pagina web e quando non si fa clic su una pagina web nelle pagine dei risultati dei motori di ricerca (SERP).
Ricordiamoci sempre che la maggior parte, se non tutti i documenti che coinvolgono il CTR riguardano il miglioramento dei risultati di ricerca e la previsione delle percentuali di clic.
Infatti il documento dice che “… identifica le selezioni dell’utente (clic) dei singoli risultati del documento e identifica anche quando l’utente torna alla pagina dei risultati, indicando quindi il tempo trascorso dall’utente a visualizzare il risultato del documento selezionato.”
Sistema di indicizzazione di Google
Secondo Roger Montti la risposta dovrebbe avere a che fare con il modo in cui Google memorizza i dati. L’indice di Google è in continuo aggiornamento dal Caffeine update. Nel 2010 il software alla base della memorizzazione di tutti i dati di Google si chiamava BigTable e il File System di Google si chiamava Colossus.
Quando parliamo di indicizzazione, stiamo parlando di Caffeina e del sistema Percolator. In un documento PDF Google spiega come funziona Percolator spiegando anche i compromessi tra il vecchio sistema file di Google che utilizzava MapReduce e il nuovo file system distribuito che esegue i calcoli in parallelo.
Nel suo articolo Roger Montti dettaglia in modo sistemico l’intero iter della elaborazione dei dati (consigliamo a tutti coloro che vogliono approfondire l’argomento di leggere l’intero articolo in lingua originale) citando più volte il documento del 2010 quando a proposito di overhead dice che Google ha “scelto un’architettura che scala in modo lineare per molti ordini di grandezza sulle commodity machine, ma abbiamo visto che questo costa un overhead significativo di 30 volte rispetto alle architetture dei database tradizionali (…)”.
Estremamente sintetizzato Google, nel suo sistema di indicizzazione chiamato MapReduce carica i documenti scansionati in Percolator mediante l’esecuzione di loader transaction che attivano la transazione del processore di documenti per indicizzare il documento (analisi, collegamenti di estrazione, ecc.). La transazione del processore di documenti attiva ulteriori transazioni come il clustering. La transazione di clusterizzazione, a sua volta, attiva le transazioni per esportare i cluster di documenti modificati nel sistema di servizio.
Ecco perché forse sarebbe più corretto parlare di una rielaborazione periodica piuttosto che l’elaborazione di una pagina o di un dominio ogni volta che viene scoperto un collegamento.
Ed è proprio questo complesso concatenarsi di operazioni che porta alla fluttuazione delle pagine nuove che hanno bisogno di tempo per potersi assestare nella SERP.
Link Graph Algorithm
Roger Montti continua la sua interessantissima analisi spiegando che secondo lui il motivo per cui si parla di ranking fluctuation per nuovi contenuti potrebbe essere dovuto al modo in cui funziona il sistema di indicizzazione e il link ranking di Google.
Come i link graph vengono generati e mantenuti
Il link graph è una mappa di Internet. Ogni volta che viene creato un nuovo collegamento o viene pubblicata una nuova pagina, il link graph cambia.
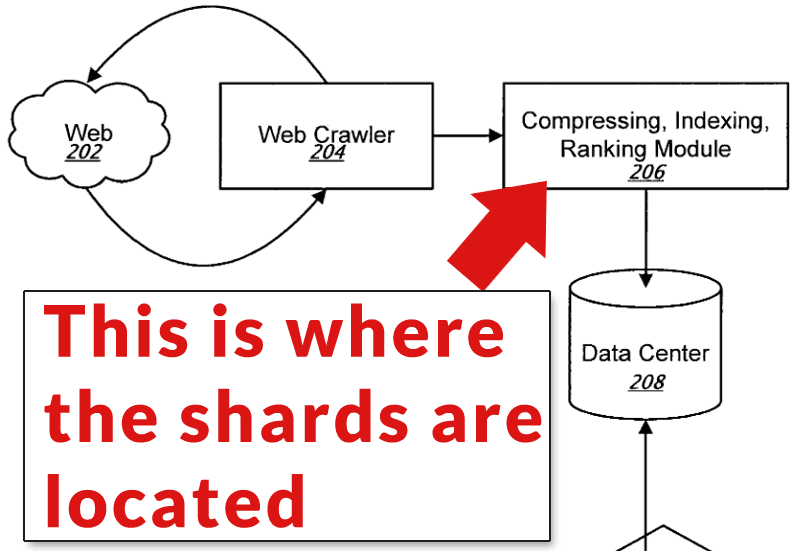
Secondo un brevetto di Google del 2009, un modo per eseguire efficientemente il calcolo del ranking dei link è quello di dividere il grafico in frammenti chiamati shard che lavorano in parallelo, ossia in contemporanea, come a dire che si va a rompere un problema in più parti andandolo a distribuire a una folla di persone che a loro volta lavorano sul loro piccolo pezzo del progetto e, alla fine, lo restituiscono al proprietario per rimetterlo insieme.
Il brevetto del 2009 dice che “assegna ciascuno dei frammenti a un rispettivo server, compresa l’assegnazione dei dati che descrivono i collegamenti associati alle risorse web multiple rappresentate dalla porzione di grafico corrispondente al frammento assegnato al server” calcolando in parallelo quanto abbiamo detto sopra.
Scorrendo l’intero documento il brevetto descrive come il web crawler scansiona Internet e memorizza le informazioni nei data center, facendoci così capire che il motore responsabile dell’indicizzazione e del ranking divide l’indice in frammenti. A questo punto il tutto viene classificato su base continua.
Il checkpointing e il tempo
Ogni frammento crea indipendentemente un checkpoint tra il suo stato attuale e l’aggiornamento. Ciò che è interessante è che viene descritto come asincrono, dove i calcoli sono fatti indipendentemente, a intervalli casuali, in qualsiasi momento, il che significa che deve aspettare che qualcos’altro finisca prima di poter iniziare l’aggiornamento o l’elaborazione.
Ogni frammento si aggiorna e ricalcola la sua sezione di Internet in base al proprio orario utilizzando una RAM per memorizzare i dati.
Nel brevetto si menziona la RAM e i tempi del ranking della pagina web ricalcolata dicendo che “una volta raggiunta una determinata dimensione, viene svuotata su un file su un disco (…) Se lo svuotamento si verifica troppo raramente o troppo lentamente, il leaf table può raggiungere dimensioni massime consentite, provocando l’interruzione dell’elaborazione degli aggiornamenti in entrata da parte del server, in modo da non esaurire la memoria. La dimensione del leaf table è un compromesso tra il consumo di memoria e la quantità di dati scritti sul disco. Più grande è la tabella, maggiori sono le possibilità di aggiornare una voce in memoria esistente prima di essere scaricata sul disco (leaf disk space)”.
Così il gioco dovrebbe essere fatto. I tempi potrebbero trovare così una correlazione con l’ottimizzazione dell’uso della RAM in modo che non diventi sovraccarico. È possibile che per un sito che viene costantemente aggiornato e che vengano costantemente aggiunti collegamenti, il tempo necessario per il posizionamento può essere più rapido.
Perché le nuove pagine rimbalzano nei risultati di ricerca
Come abbiamo visto la risposta a una domanda apparentemente semplice come “perché le nuove pagine fluttuano nei risultati di ricerca di Google” può dimostrarsi straordinariamente complessa.
È facile lanciare ipotesi casuali come Google sta monitorando i clic e le metriche di soddisfazione degli utenti. Ma non ci sono prove scientifiche e brevetti pubblicati da Google per sostenere che si tratti di clic di tracciamento di Google.
John Mueller ha semplicemente affermato che le nuove pagine sono soggette a fluttuazioni estreme (come indicato nel link all’inizio di questo articolo). Le ragioni, come ho delineato in questo articolo, potrebbero essere molte. Ho evidenziato molti di questi motivi.
[via searchenginejournal.com]







